





















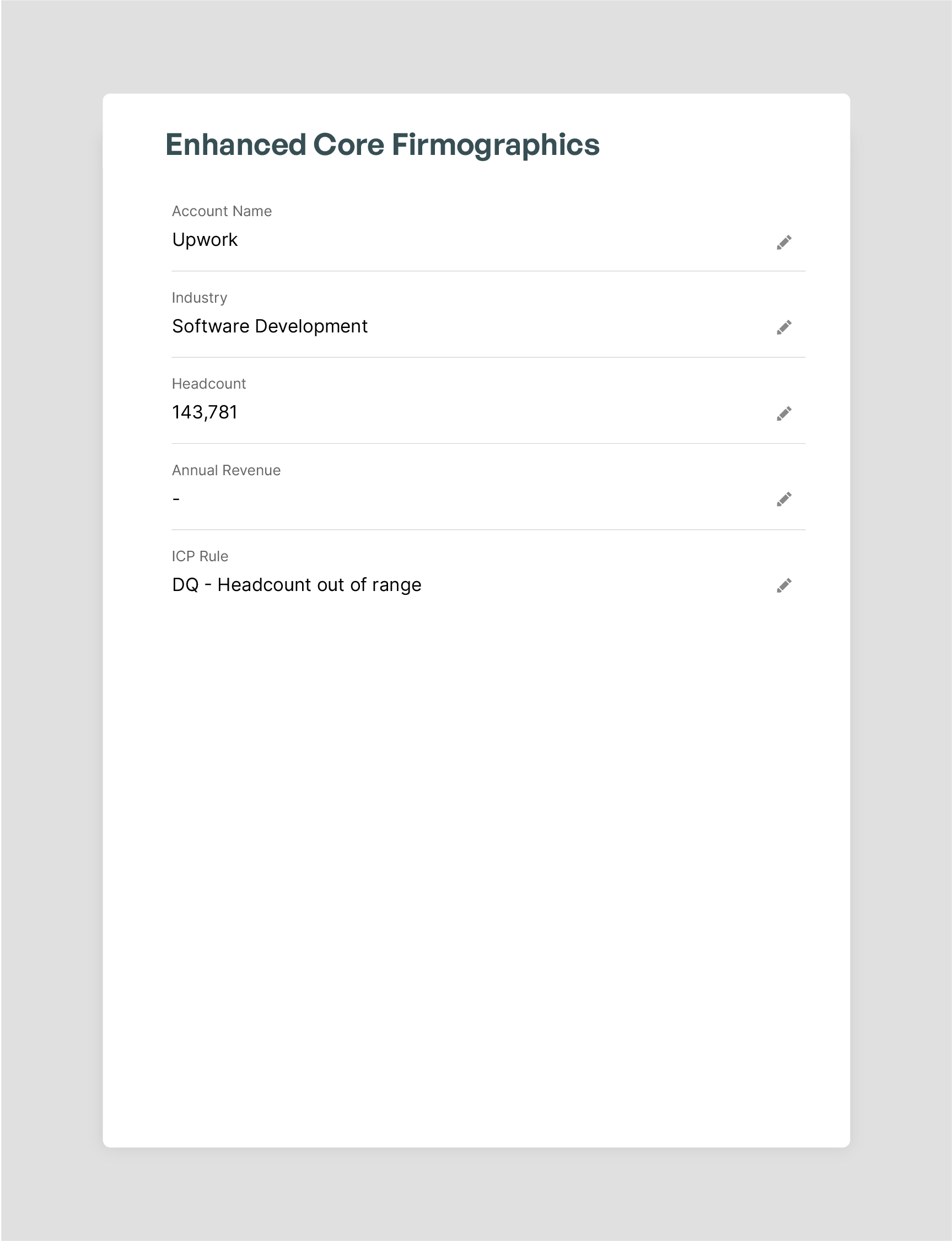
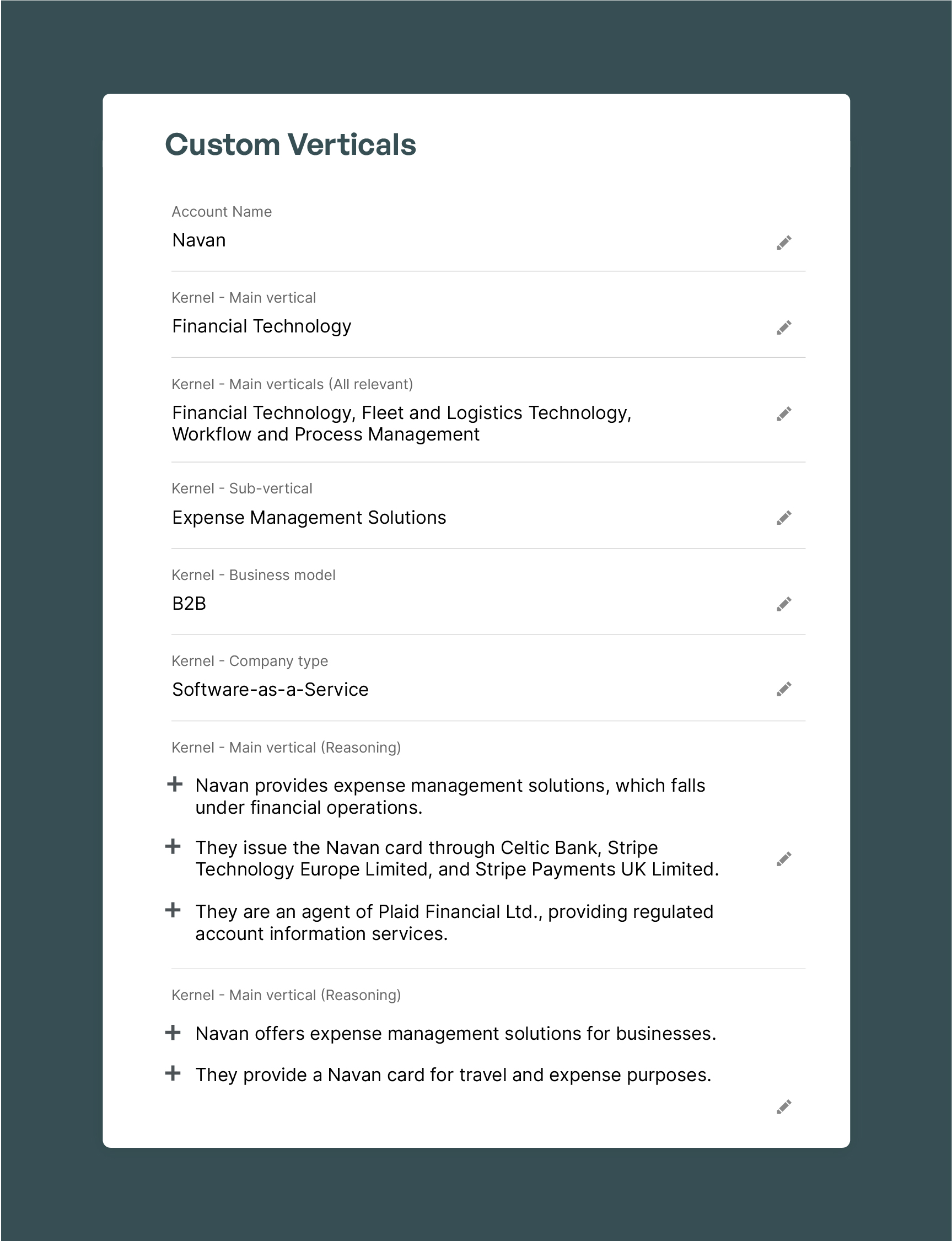
Kernel improves and validates core firmographic enrichment accuracy with multiple high-context and high-fidelity data sources.
Where generic enrichment uses single sources to identify headcount, revenue, location, and the age of a company, Kernel uses all public information to develop accurate enrichment.
Combining unstructured and structured data enables Kernel’s complex estimations models. Kernel’s master data accuracy ensures hallucinations and inaccuracies are not added to the CRM.
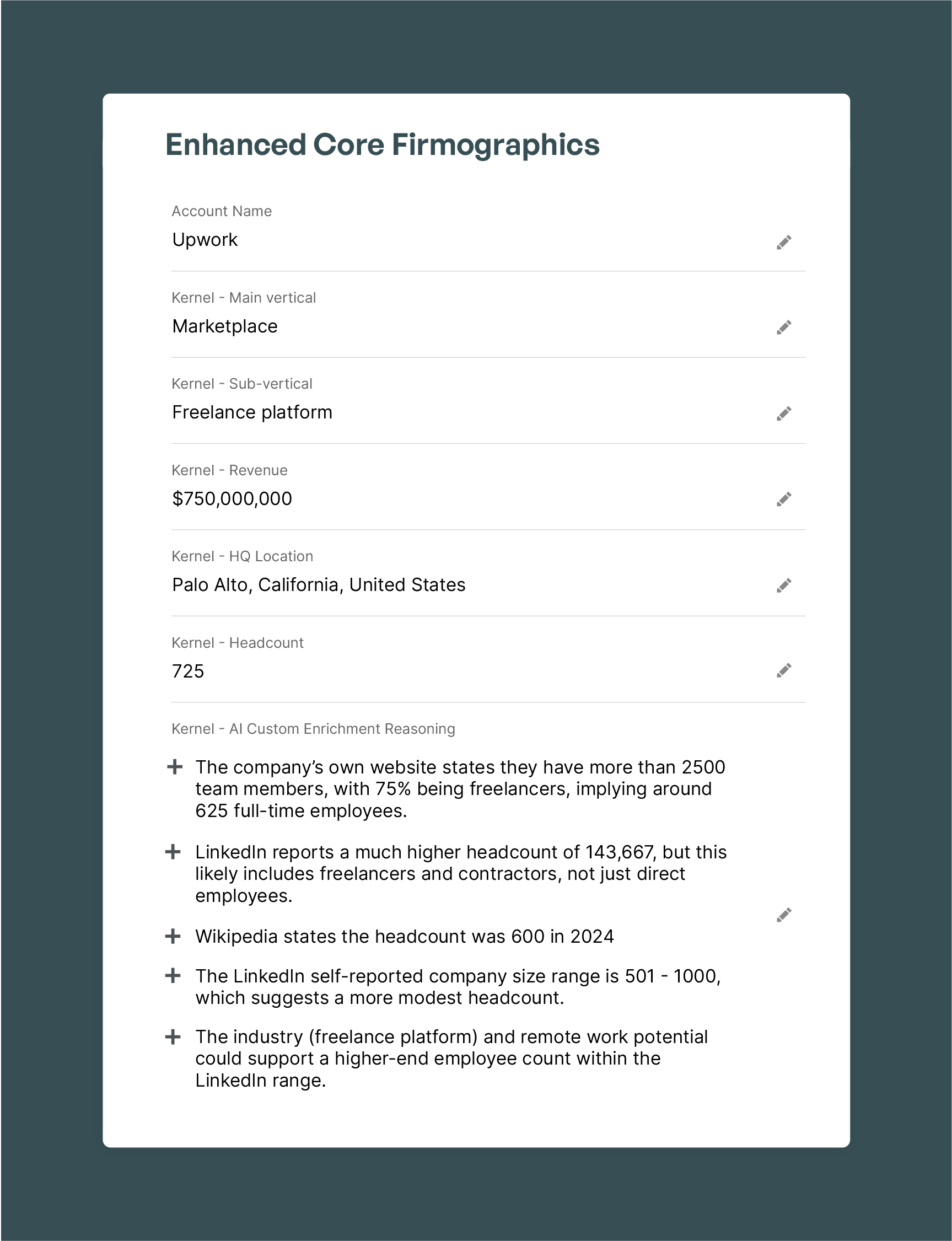
Kernel Headcount:
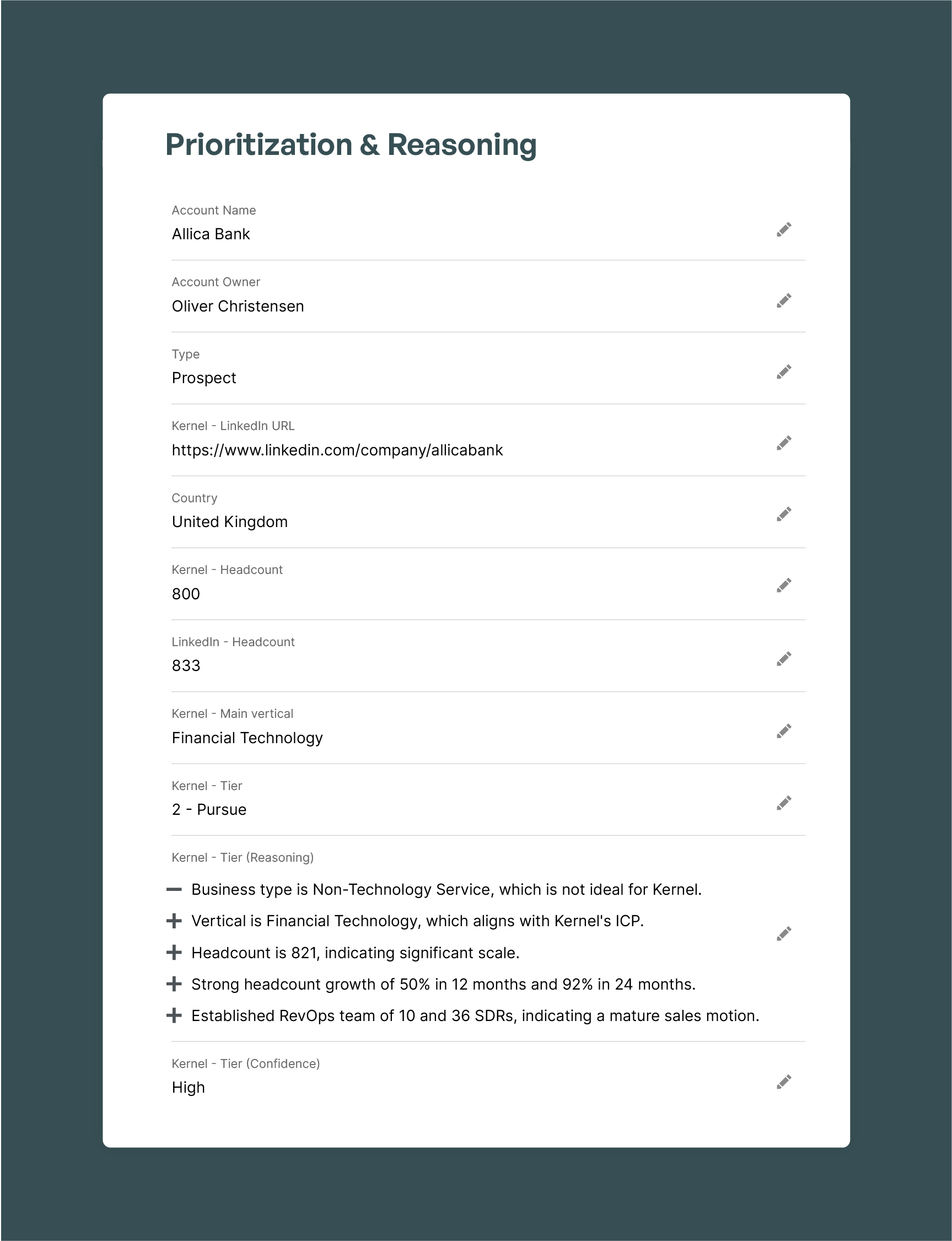
Kernel determines headcount by first checking primary sources like:
If no direct evidence is available, Kernel uses LinkedIn data as a fallback. Kernel’s AI module cross-checks the LinkedIn headcount against the company's self-reported size and adjusts the figure based on the company's industry, country, and growth rate.
If no LinkedIn is available, Kernel uses other data points available about the company on the web to provide an accurate headcount figure such as registries and employment disclosures.
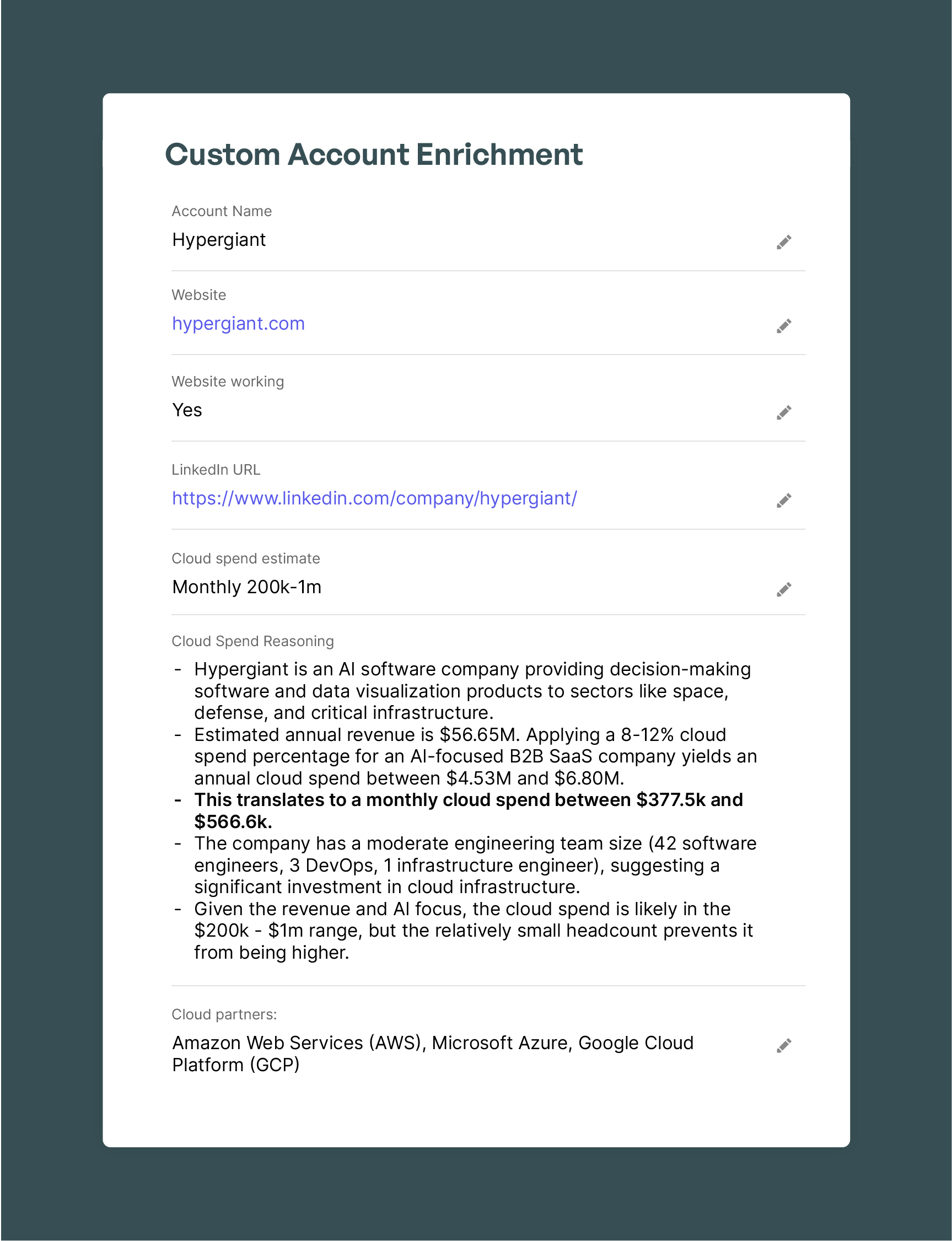
Kernel Revenue:
When available, Kernel sources revenue figures directly from primary sources like:
If a number is not publicly reported, Kernel uses a custom estimation model that analyzes factors like industry benchmarks, company type, web traffic, and headcount to produce an estimate.

















.png)
